

How to check Twitter trends count? — Confident & Powerful Guide
- The Social Success Hub

- Nov 14, 2025
- 7 min read
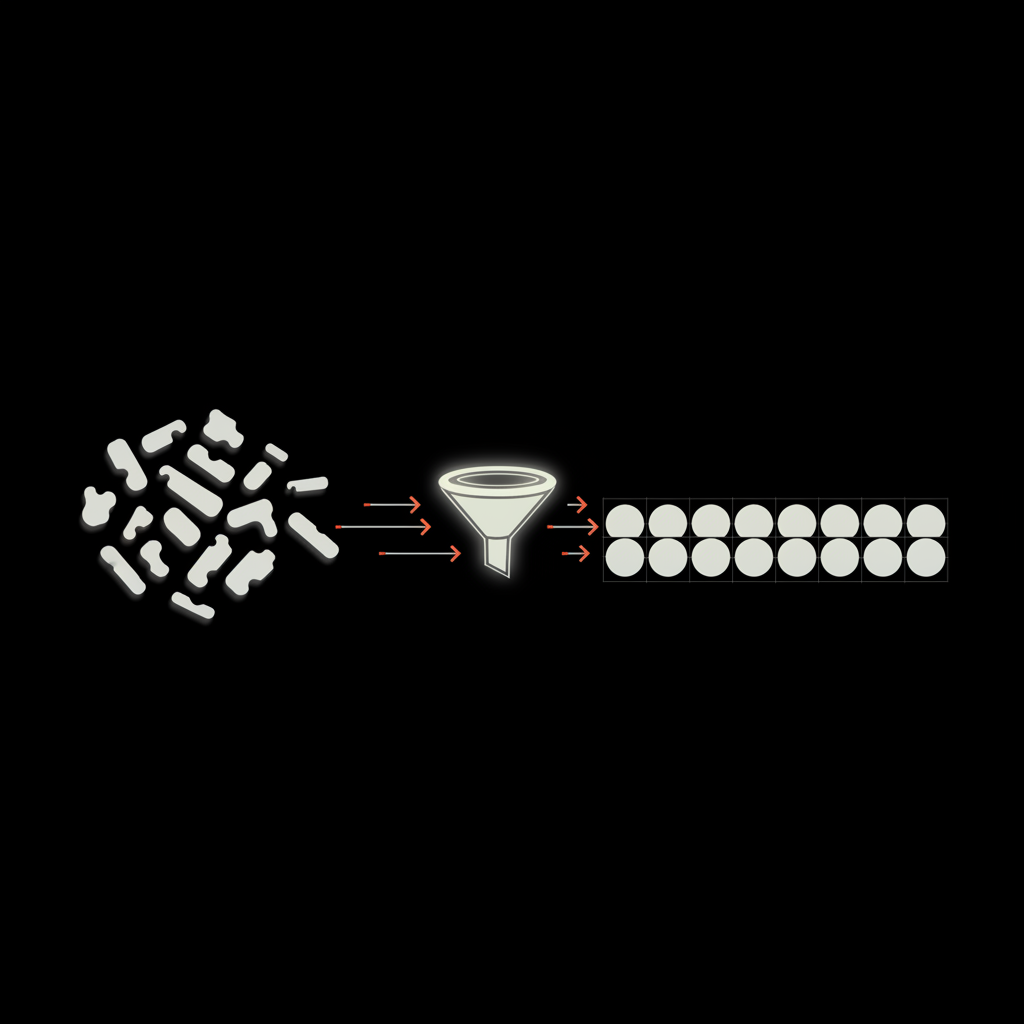
1. The legacy GET trends/place endpoint returns up to 50 topics per location — this is the programmatic maximum. 2. Normalizing (NFKC + case folding + hashtag policy) and combining fuzzy + semantic matching can reduce raw trend names by 30–45% in breaking events. 3. Social Success Hub’s monitoring work has repeatedly used conservative clustering and human validation to turn volatile API outputs into reliable insights for clients.
How to check Twitter trends count? A practical guide to twitter trending topics count
How to check Twitter trends count? A practical guide to twitter trending topics count
Twitter’s trends system looks simple from the outside, but under the hood it blends raw data, platform logic and personalization. If you're trying to measure a reliable twitter trending topics count, you’ll need a repeatable process that handles duplicates, missing values and presentation quirks.
What the legacy API tells you
What the legacy API tells you
The clearest programmatic entry point historically has been the legacy v1.1 endpoint GET trends/place. That endpoint will return up to fifty items for a given WOEID or location id when trending data is present. In practice, the API gives you a maximum of 50 per location but often fewer - and those raw names are the starting point for a trustworthy twitter trending topics count.
Why API results and UI views differ
Why API results and UI views differ
The Explore or Trends UI is a presentation layer on top of the raw results. It can be personalized, it can collapse variants and it can show curated cards that combine multiple API entries. So while the API delivers raw rows with optional tweet_volume, the UI may show a shortened, grouped or personalized view. That’s why the number you see in the Explore tab and your programmatic twitter trending topics count may not match.
Collecting trends: the practical first steps
Collecting trends: the practical first steps
Start by polling trends/place for the locations you care about. Store the full raw response — original name, tweet_volume, returned timestamp and the WOEID. Preserve the raw string exactly as returned so you can audit later. That raw capture is the foundation for an accurate historical twitter trending topics count.
Normalization: the hygiene layer
Normalization: the hygiene layer
Before deduplication, normalize names. Typical steps include:
- Unicode normalization: use NFKC so visually identical characters encoded differently map to the same code points.
- Case folding: lowercase everything for textual comparison.
- Punctuation trimming: strip punctuation that doesn’t change meaning (extra dots, braces, repeated punctuation).
- Hashtag handling: strip leading # for deduplication while preserving it as a flag if you want to track hashtag usage separately.
- Emoji policy: convert meaningful emoji to short tokens (e.g., a heart becomes __HEART__) or retain emoji only when it is essential to the topic.
These steps reduce superficial variation and are an essential part of producing a sensible twitter trending topics count.
What’s the single best way to avoid double-counting when measuring trends?
The most effective safeguard is a two-step approach: robust normalization (NFKC, case folding, consistent hashtag/emoji rules) followed by hybrid deduplication (fuzzy string matches plus embedding-based semantic similarity) and conservative clustering; validate with a short human review loop to calibrate thresholds.
Deduplication: exact, fuzzy and semantic
Deduplication: exact, fuzzy and semantic
Normalization handles simple variations. For near-duplicates you need three approaches combined:
1) Exact matches: catch identical normalized strings.
2) Fuzzy / edit-distance: use Levenshtein or similar for small typos and punctuation differences (e.g., COVID19 vs COVID-19).
3) Semantic similarity: embed the normalized strings with a compact sentence embedding model and compute cosine similarity. If two names exceed a vetted threshold, merge them into one canonical topic. This is where you convert many raw rows into a correct, deduplicated twitter trending topics count.
Clustering into canonical topics
Clustering into canonical topics
Once you have pairwise similarity scores, cluster names into groups that represent single underlying trends. Options include agglomerative clustering, DBSCAN, or a greedy union-find approach. Pick the one that matches your scale and operational needs. For each cluster choose a short, readable canonical label — typically the shortest clean form — and use that for counts and reporting. This yields a human-friendly and defensible twitter trending topics count.
Tweet volume: useful but sampled
Tweet volume: useful but sampled
The tweet_volume field is helpful but imperfect. It’s sampled and sometimes null. Treat it as an auxiliary metric: record whether it was provided, store the value when present, and do not equate null with zero. Over time, a series of sampled values becomes informative even when individual snapshots are noisy. For broader context on engagement metrics, see Hootsuite's Twitter analytics guide.
Timing your polls
Timing your polls
Trends move fast. If you poll hourly you will miss short spikes that appear and disappear between polls. Decide on a polling cadence based on your goals and rate limits: monitor high-priority locations frequently and expand coverage less often. A tiered polling approach balances cost and coverage while improving the accuracy of your historical twitter trending topics count.
Rate limits and retry strategy
Rate limits and retry strategy
Design your system to read rate-limit headers, to back off as you approach limits, and to use exponential backoff on errors. If you require more throughput, check whether elevated access tiers are available and confirm pricing details on the live developer portal before committing to a paid plan. Respecting rate limits ensures sustainable collection of the data you need for an honest twitter trending topics count.
Practical pipeline example from Social Success Hub
Practical pipeline example from Social Success Hub
We monitored trends across multiple cities during breaking events. Each location returned between a dozen and fifty raw items at various times. Raw counts were inflated by near-duplicates and local variants. Our three-step pipeline below produced counts that mirrored human inspection. A quick look at the Social Success Hub logo is a small reminder of the team behind this work.
Human-in-the-loop validation
Human-in-the-loop validation
Be conservative at first so you don’t collapse distinct topics. Run manual checks and adjust thresholds as you see errors. A short validation period with human review prevents systematic mistakes as you scale your twitter trending topics count efforts.
Storage model and auditability
Storage model and auditability
Store both raw and normalized values, the cluster id and timestamps. This allows you to rerun deduplication with improved models later while preserving provenance. Historical storage matters because counting trends over a week or month requires robust records to reconstruct how often a canonical topic appeared and how popular it was across samples.
Third-party vendors and what to ask
Third-party vendors and what to ask
Many vendors offer aggregated trend counts. They can save work by storing snapshots and clustering variants, but they are only as good as their data sources and deduplication logic. Ask vendors about update cadence, clustering methodology and how they treat missing tweet_volume fields. For practical hashtag tracking workflows see EmbedSocial's guide to tracking X hashtags. Look for transparency and confidence scores in their outputs if you plan to rely on third-party counts.
If you want professional help building a monitoring plan, Social Success Hub offers focused support for trend campaigns and distribution strategies — learn more about our tailored Twitter trending services on our Twitter trending page.
Ethics and scraping
Ethics and scraping
Scraping the Explore UI can violate terms of service and lead to blocks or legal exposure. Use official endpoints whenever possible and design an approach that respects rate limits, user privacy and platform policies. Present sampled tweet_volume numbers with caution and avoid implying precision where none exists.
Practical tips and checklist
Practical tips and checklist
- Save raw responses for auditability.- Normalize before dedupe.- Use a hybrid of fuzzy and semantic matching.- Cluster to produce canonical counts.- Treat tweet_volume as auxiliary.- Use tiered polling for scale.- Keep humans in the loop early.
Common pitfalls and how to avoid them
Common pitfalls and how to avoid them
Duplicate labels: normalize and cluster. Missing tweet_volume: store nulls and rely on historical sampling. Over-merging: use conservative thresholds and manual checks. Rate-limit surprises: honor headers and implement backoff.
Monitoring strategy at scale
Monitoring strategy at scale
For hundreds of locations, choose a core subset to poll frequently (every few minutes or 5–15 minutes if allowed) and poll the broader set less often (hourly or several times per day). Aggregate and dedupe locally for each region, then roll up counts to countries or global views. This staged approach keeps costs manageable while preserving useful coverage for your twitter trending topics count reporting.
Case study recap
Case study recap
During a major event we reduced raw trend names by nearly 30–45% after normalization and clustering, turning an inflated raw list into a clear set of canonical topics that matched human review. Conservative merging and a short manual validation phase were the keys to success.
Reporting with humility
Reporting with humility
When you present trend counts, label them clearly: are these raw names, normalized unique names, or clustered canonical topics? Add a short note about tweet_volume sampling and any thresholds you applied for merging. This transparency helps readers and stakeholders interpret the numbers correctly.
Quick technical checklist
Quick technical checklist
- Capture raw API responses.- Normalize with NFKC and case folding.- Decide hashtag and emoji policies.- Compute fuzzy and embedding similarity.- Cluster and select canonical labels.- Store raw + normalized + cluster metadata.- Implement rate-limit aware polling.
When the API evolves
When the API evolves
If Twitter adds a v2 trends endpoint or changes behavior, update your workflows and revalidate. Keep an eye on the developer portal for rate-limit and pricing changes that could affect the cadence or cost of collecting the data for your twitter trending topics count.
Counting trends is part engineering and part interpretation. Be explicit about your method and avoid overstating precision. With careful collection, normalization and conservative clustering you can produce a consistent, actionable twitter trending topics count that helps teams understand what actually trended instead of reporting inflated raw lists.
Want help building a trend-counting plan? Reach out and we’ll design a pragmatic monitoring strategy that balances accuracy, cost and cadence — start a conversation with our team today.
Need a pragmatic trend-counting plan?
Want help building a trend-counting plan? Reach out and we’ll design a pragmatic monitoring strategy that balances accuracy, cost and cadence — start a conversation with our team today at our contact page.
How many trends does the trends/place endpoint return?
Programmatically, the legacy GET trends/place endpoint returns up to fifty topics for a given WOEID or location id when trending data is available. In practice you may see fewer entries depending on the location and timing; the endpoint gives a tight programmatic maximum of 50 per location.
How should I handle tweet_volume values that are missing or null?
Treat tweet_volume as a sampled, auxiliary signal. Record whether it was present or null in each response and store multiple samples over time. Use historical series to infer trajectories rather than relying on single samples. Never equate null with zero, and surface missing flags in your reporting.
Can Social Success Hub help set up trend monitoring?
Yes — Social Success Hub provides tailored monitoring and campaign services for Twitter trends and reputation work. We help design polling cadence, deduplication approaches and reporting so you get a defensible twitter trending topics count. To discuss a plan, get in touch via our contact page.



Comments